Challenges of Large Language Models
Large Language Models (LLMs) like ChatGPT have significantly advanced natural language processing by enabling machines to understand and generate human-like text. However, developing and deploying these models present several challenges:
- Output Quality and Hallucinations: Ensuring high-quality outputs is difficult as LLMs can sometimes produce incorrect or nonsensical responses, making them unreliable.
- AI Safety and Privacy: Rapid advancements in LLMs bring safety concerns, requiring adherence to ethical guidelines to prevent harmful or biased content.
- Compute, Cost, and Time-Intensive Workloads: LLMs demand substantial computational resources for training, which can be costly and time-consuming.
General Cost of Building an LLM
Training LLMs is resource-intensive, illustrated by the GPU hours required:
- Llama 2 (7b): ~180,000 GPU hours
- Llama 2 (70b): ~1,700,000 GPU hours
- Estimated Costs:
- 10b model: ~100,000 GPU hours, costing approximately $150,000 if renting GPUs.
- 100b model: ~1,000,000 GPU hours, costing approximately $1,500,000 if renting GPUs.
- Owning GPU Hardware: A cluster of Nvidia A100 GPUs would cost around $10,000,000, with additional training energy costs (for a 100b model) of about $100,000, leading to a total of $10,100,000.
To provide context, ChatGPT-3.5 has 175 billion parameters, and ChatGPT-4.0 is estimated to have 1.76 trillion parameters.
Proposed Solutions
Given the high costs and complexity of building LLMs from scratch, leveraging existing models is a more feasible approach. This can be achieved through:
- Model Fine-Tuning: Customizing a pre-trained model to better suit specific tasks or datasets.
- Context Injection: Enhancing the model’s performance by providing it with relevant context during operation.
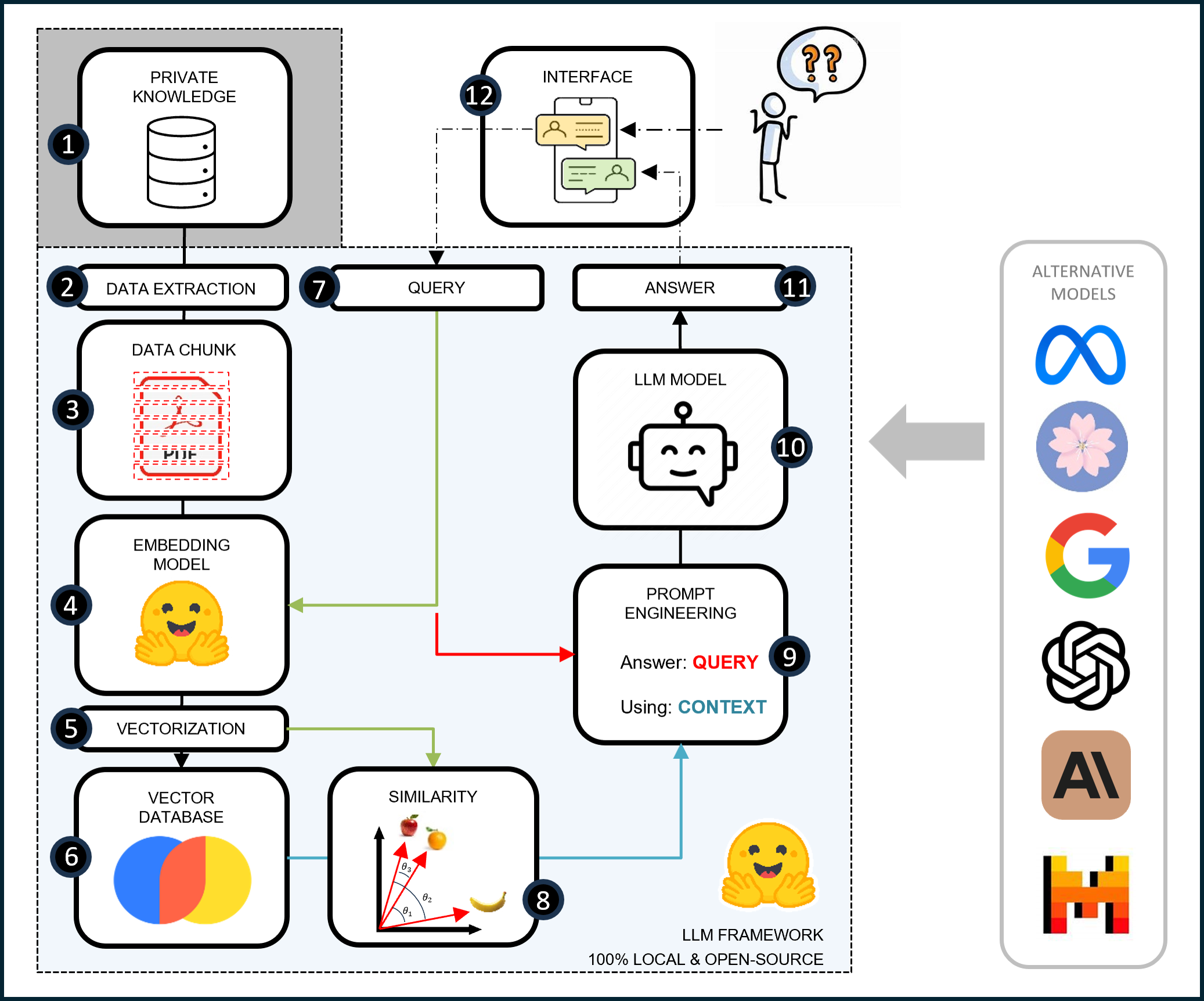
Retrieval-Augmented Generation (RAG)
One form of context injection is known as Retrieval-Augmented Generation (RAG). RAG combines LLMs with a retrieval system to improve performance and address key challenges:
- Preserving Data Privacy: Locally hosting and running models on secure information.
- Mitigating LLM Hallucinations: Using a reliable database to ensure accuracy.
- Real-Time Data Access: Empowering LLMs with up-to-date information.
Applications
- Knowledge Sharing: Using LLMs to disseminate information through journals, leaflets, and websites.
- Report/Journal Summarization and Content Extraction: Automating the summarization of internal documents.
- Writing Aids: Assisting in marketing, coding, data analysis, and research.
- Knowledge Management: Enhancing database management and information retrieval.
By automating mundane tasks, LLMs free up valuable time for creative and strategic activities, increasing overall productivity and efficiency.
Github Repository
Github Repository Link